Kafka生产者分区策略 – 掘金 (juejin.cn)
kafka key的作用一探究竟,详解Kafka生产者和消费者的工作原理!-腾讯云开发者社区-腾讯云 (tencent.com)
kafka 生产调优-生产常用参数配置 – 知乎 (zhihu.com)
彻底理解kafka中partition和消费者对应关系_kafka partition consumer 对应关系_慕城南风的博客-CSDN博客
kafka key的作用一探究竟,详解Kafka生产者和消费者的工作原理!-腾讯云开发者社区-腾讯云 (tencent.com)
kafka 生产调优-生产常用参数配置 – 知乎 (zhihu.com)
彻底理解kafka中partition和消费者对应关系_kafka partition consumer 对应关系_慕城南风的博客-CSDN博客
大概如下:
Bean 的生命周期
如上图所示,Bean 的生命周期还是比较复杂的,下面来对上图每一个步骤做文字描述:
Spring启动,查找并加载需要被Spring管理的bean,进行Bean的实例化
Bean实例化后对将Bean的引入和值注入到Bean的属性中
如果Bean实现了BeanNameAware接口的话,Spring将Bean的Id传递给setBeanName()方法
如果Bean实现了BeanFactoryAware接口的话,Spring将调用setBeanFactory()方法,将BeanFactory容器实例传入
如果Bean实现了ApplicationContextAware接口的话,Spring将调用Bean的setApplicationContext()方法,将bean所在应用上下文引用传入进来。
如果Bean实现了BeanPostProcessor接口,Spring就将调用他们的postProcessBeforeInitialization()方法。
如果bean有被@PostConstruct注解的方法,会执行该方法;如果Bean 实现了InitializingBean接口,Spring将调用他们的afterPropertiesSet()方法。类似的,如果bean使用init-method声明了初始化方法,该方法也会被调用
如果Bean 实现了BeanPostProcessor接口,Spring就将调用他们的postProcessAfterInitialization()方法。
此时,Bean已经准备就绪,可以被应用程序使用了。他们将一直驻留在应用上下文中,直到应用上下文被销毁。
如果bean有被@PreDestroy注解的方法,执行该方法;如果bean实现了DisposableBean接口,Spring将调用它的destory()接口方法,同样,如果bean使用了destory-method 声明销毁方法,该方法也会被调用。
————————————————
版权声明:本文为CSDN博主「秃头小魔王」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_32780741/article/details/106317438
接口性能问题,对于从事后端开发的同学来说,是一个绕不开的话题。想要优化一个接口的性能,需要从多个方面着手。
其实,我之前也写过一篇接口性能优化相关的文章《聊聊接口性能优化的11个小技巧》,发表之后在全网广受好评,感兴趣的小伙们可以仔细看看。
本文将会接着接口性能优化这个话题,从实战的角度出发,聊聊我是如何优化一个慢查询接口的。
上周我优化了一下线上的批量评分查询接口,将接口性能从最初的20s,优化到目前的500ms以内。
总体来说,用三招就搞定了。
到底经历了什么?
我们每天早上上班前,都会收到一封线上慢查询接口汇总邮件,邮件中会展示接口地址、调用次数、最大耗时、平均耗时和traceId等信息。
我看到其中有一个批量评分查询接口,最大耗时达到了20s,平均耗时也有2s。
用skywalking查看该接口的调用信息,发现绝大数情况下,该接口响应还是比较快的,大部分情况都是500ms左右就能返回,但也有少部分超过了20s的请求。
这个现象就非常奇怪了。
莫非跟数据有关?
比如:要查某一个组织的数据,是非常快的。但如果要查平台,即组织的根节点,这种情况下,需要查询的数据量非常大,接口响应就可能会非常慢。
但事实证明不是这个原因。
很快有个同事给出了答案。
他们在结算单列表页面中,批量请求了这个接口,但他传参的数据量非常大。
怎么回事呢?
当初说的需求是这个接口给分页的列表页面调用,每页大小有:10、20、30、50、100,用户可以选择。
换句话说,调用批量评价查询接口,一次性最多可以查询100条记录。
但实际情况是:结算单列表页面还包含了很多订单。基本上每一个结算单,都有多个订单。调用批量评价查询接口时,需要把结算单和订单的数据合并到一起。
这样导致的结果是:调用批量评价查询接口时,一次性传入的参数非常多,入参list中包含几百、甚至几千条数据都有可能。
如果一次性传入几百或者几千个id,批量查询数据还好,可以走主键索引,查询效率也不至于太差。
但那个批量评分查询接口,逻辑不简单。
伪代码如下:
public List<ScoreEntity> query(List<SearchEntity> list) {
//结果
List<ScoreEntity> result = Lists.newArrayList();
//获取组织id
List<Long> orgIds = list.stream().map(SearchEntity::getOrgId).collect(Collectors.toList());
//通过regin调用远程接口获取组织信息
List<OrgEntity> orgList = feginClient.getOrgByIds(orgIds);
for(SearchEntity entity : list) {
//通过组织id找组织code
String orgCode = findOrgCode(orgList, entity.getOrgId());
//通过组合条件查询评价
ScoreSearchEntity scoreSearchEntity = new ScoreSearchEntity();
scoreSearchEntity.setOrgCode(orgCode);
scoreSearchEntity.setCategoryId(entity.getCategoryId());
scoreSearchEntity.setBusinessId(entity.getBusinessId());
scoreSearchEntity.setBusinessType(entity.getBusinessType());
List<ScoreEntity> resultList = scoreMapper.queryScore(scoreSearchEntity);
if(CollectionUtils.isNotEmpty(resultList)) {
ScoreEntity scoreEntity = resultList.get(0);
result.add(scoreEntity);
}
}
return result;
}其实在真实场景中,代码比这个复杂很多,这里为了给大家演示,简化了一下。
最关键的地方有两点:
其中的第1点,即:在接口中远程调用了另外一个接口,这个代码是必须的。
因为如果在评价表中冗余一个组织code字段,万一哪天组织表中的组织code有修改,不得不通过某种机制,通知我们同步修改评价表的组织code,不然就会出现数据不一致的问题。
很显然,如果要这样调整的话,业务流程上要改了,代码改动有点大。
所以,还是先保持在接口中远程调用吧。
这样看来,可以优化的地方只能在:for循环中查询数据。
由于需要在for循环中,每条记录都要根据不同的条件,查询出想要的数据。
由于业务系统调用这个接口时,没有传id,不好在where条件中用id in (...),这方式批量查询数据。
其实,有一种办法不用循环查询,一条sql就能搞定需求:使用or关键字拼接,例如:(org_code=’001′ and category_id=123 and business_id=111 and business_type=1) or (org_code=’002′ and category_id=123 and business_id=112 and business_type=2) or (org_code=’003′ and category_id=124 and business_id=117 and business_type=1)…
这种方式会导致sql语句会非常长,性能也会很差。
其实还有一种写法:
where (a,b) in ((1,2),(1,3)...)不过这种sql,如果一次性查询的数据量太多的话,性能也不太好。
居然没法改成批量查询,就只能优化单条查询sql的执行效率了。
首先从索引入手,因为改造成本最低。
第一次优化是
优化索引。
评价表之前建立一个business_id字段的普通索引,但是从目前来看效率不太理想。
由于我果断加了联合索引:
alter table user_score add index `un_org_category_business` (`org_code`,`category_id`,`business_id`,`business_type`) USING BTREE;该联合索引由:org_code、category_id、business_id和business_type四个字段组成。
经过这次优化,效果立竿见影。
批量评价查询接口最大耗时,从最初的20s,缩短到了5s左右。
由于需要在for循环中,每条记录都要根据不同的条件,查询出想要的数据。
只在一个线程中查询数据,显然太慢。
那么,为何不能改成多线程调用?
第二次优化,查询数据库由
单线程改成多线程。
但由于该接口是要将查询出的所有数据,都返回回去的,所以要获取查询结果。
使用多线程调用,并且要获取返回值,这种场景使用java8中的CompleteFuture非常合适。
代码调整为:
CompletableFuture[] futureArray = dataList.stream()
.map(data -> CompletableFuture
.supplyAsync(() -> query(data), asyncExecutor)
.whenComplete((result, th) -> {
})).toArray(CompletableFuture[]::new);
CompletableFuture.allOf(futureArray).join();CompleteFuture的本质是创建线程执行,为了避免产生太多的线程,所以使用线程池是非常有必要的。
优先推荐使用ThreadPoolExecutor类,我们自定义线程池。
具体代码如下:
ExecutorService threadPool = new ThreadPoolExecutor(
8, //corePoolSize线程池中核心线程数
10, //maximumPoolSize 线程池中最大线程数
60, //线程池中线程的最大空闲时间,超过这个时间空闲线程将被回收
TimeUnit.SECONDS,//时间单位
new ArrayBlockingQueue(500), //队列
new ThreadPoolExecutor.CallerRunsPolicy()); //拒绝策略也可以使用ThreadPoolTaskExecutor类创建线程池:
@Configuration
public class ThreadPoolConfig {
/**
* 核心线程数量,默认1
*/
private int corePoolSize = 8;
/**
* 最大线程数量,默认Integer.MAX_VALUE;
*/
private int maxPoolSize = 10;
/**
* 空闲线程存活时间
*/
private int keepAliveSeconds = 60;
/**
* 线程阻塞队列容量,默认Integer.MAX_VALUE
*/
private int queueCapacity = 1;
/**
* 是否允许核心线程超时
*/
private boolean allowCoreThreadTimeOut = false;
@Bean("asyncExecutor")
public Executor asyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(maxPoolSize);
executor.setQueueCapacity(queueCapacity);
executor.setKeepAliveSeconds(keepAliveSeconds);
executor.setAllowCoreThreadTimeOut(allowCoreThreadTimeOut);
// 设置拒绝策略,直接在execute方法的调用线程中运行被拒绝的任务
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
// 执行初始化
executor.initialize();
return executor;
}
}经过这次优化,接口性能也提升了5倍。
从5s左右,缩短到1s左右。
但整体效果还不太理想。
经过前面的两次优化,批量查询评价接口性能有一些提升,但耗时还是大于1s。
出现这个问题的根本原因是:一次性查询的数据太多。
那么,我们为什么不限制一下,每次查询的记录条数呢?
第三次优化,限制一次性查询的记录条数。其实之前也做了限制,不过最大是2000条记录,从目前看效果不好。
限制该接口一次只能查200条记录,如果超过200条则会报错提示。
如果直接对该接口做限制,则可能会导致业务系统出现异常。
为了避免这种情况的发生,必须跟业务系统团队一起讨论一下优化方案。
主要有下面两个方案:
在结算单列表页中,每个结算单默认只展示1个订单,多余的分页查询。
这样的话,如果按照每页最大100条记录计算的话,结算单和订单最多一次只能查询200条记录。
这就需要业务系统的前端做分页功能,同时后端接口要调整支持分页查询。
但目前现状是前端没有多余开发资源。
由于人手不足的原因,这套方案目前只能暂时搁置。
业务系统后端之前是一次性调用评价查询接口,现在改成分批调用。
比如:之前查询500条记录,业务系统只调用一次查询接口。
现在改成业务系统每次只查100条记录,分5批调用,总共也是查询500条记录。
这样不是变慢了吗?
答:如果那5批调用评价查询接口的操作,是在for循环中单线程顺序的,整体耗时当然可能会变慢。
但业务系统也可以改成多线程调用,只需最终汇总结果即可。
此时,有人可能会问题:在评价查询接口的服务器多线程调用,跟在其他业务系统中多线程调用不是一回事?
还不如把批量评价查询接口的服务器中,线程池的最大线程数调大一点?
显然你忽略了一件事:线上应用一般不会被部署成单点。绝大多数情况下,为了避免因为服务器挂了,造成单点故障,基本会部署至少2个节点。这样即使一个节点挂了,整个应用也能正常访问。
当然也可能会出现这种情况:假如挂了一个节点,另外一个节点可能因为访问的流量太大了,扛不住压力,也可能因此挂掉。
换句话说,通过业务系统中的多线程调用接口,可以将访问接口的流量负载均衡到不同的节点上。
他们也用8个线程,将数据分批,每批100条记录,最后将结果汇总。
经过这次优化,接口性能再次提升了1倍。
从1s左右,缩短到小于500ms。
温馨提醒一下,无论是在批量查询评价接口查询数据库,还是在业务系统中调用批量查询评价接口,使用多线程调用,都只是一个临时方案,并不完美。
这样做的原因主要是为了先快速解决问题,因为这种方案改动是最小的。
要从根本上解决问题,需要重新设计这一套功能,需要修改表结构,甚至可能需要修改业务流程。但由于牵涉到多条业务线,多个业务系统,只能排期慢慢做了。
批量思想:批量操作数据库,这个很好理解,我们在循环插入场景的接口中,可以在批处理执行完成后一次性插入或更新数据库,避免多次 IO。
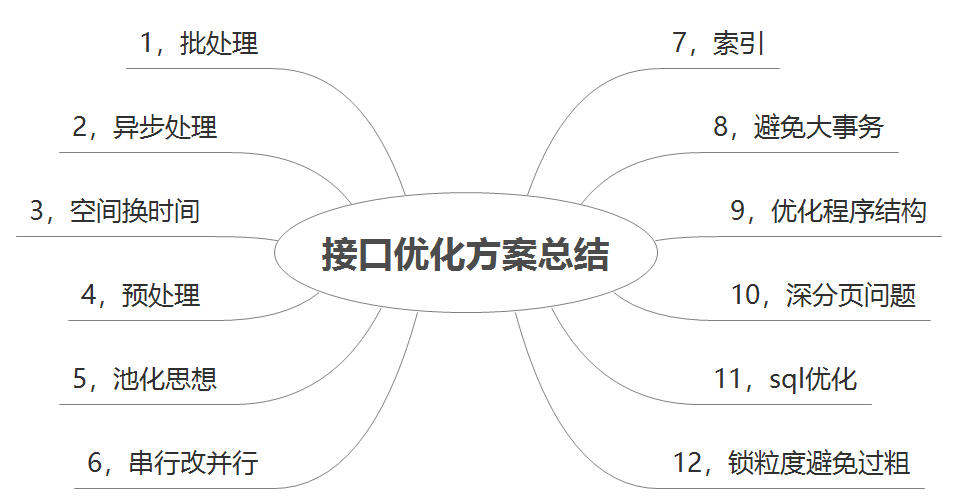
批量思想:批量操作数据库,这个很好理解,我们在循环插入场景的接口中,可以在批处理执行完成后一次性插入或更新数据库,避免多次 IO。
//for循环单笔入库
list.stream().forEatch(msg->{
insert();
});
//批量入库
batchInsert();异步思想:针对耗时比较长且不是结果必须的逻辑,我们可以考虑放到异步执行,这样能降低接口耗时。
例如一个理财的申购接口,入账和写入申购文件是同步执行的,因为是 T+1 交易,后面这两个逻辑其实不是结果必须的,我们并不需要关注它的实时结果,所以我们考虑把入账和写入申购文件改为异步处理。如图所示:
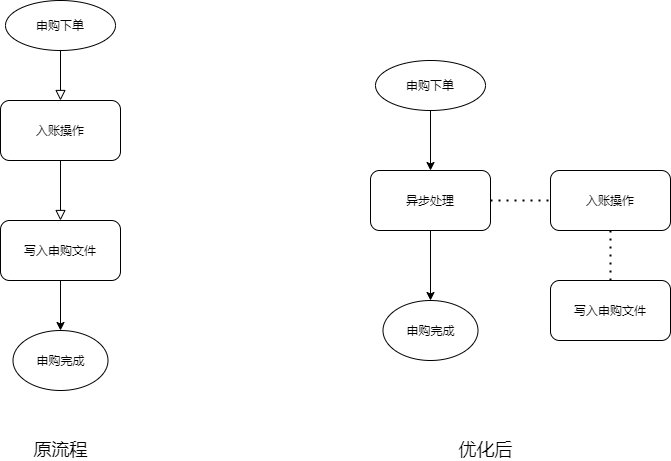
至于异步的实现方式,可以用线程池,也可以用消息队列,还可以用一些调度任务框架。
一个很好理解的空间换时间的例子是合理使用缓存,针对一些频繁使用且不频繁变更的数据,可以提前缓存起来,需要时直接查缓存,避免频繁地查询数据库或者重复计算。
需要注意的事,这里用了合理二字,因为空间换时间也是一把双刃剑,需要综合考虑你的使用场景,毕竟缓存带来的数据一致性问题也挺令人头疼。
这里的缓存可以是 R2M,也可以是本地缓存、memcached,或者 Map。
举一个股票工具的查询例子:
因为策略轮动的调仓信息,每周只更新一次,所以原来的调接口就去查库的逻辑并不合理,而且拿到调仓信息后,需要经过复杂计算,最终得出回测收益和跑赢沪深指数这些我们想要的结果。如果我们把查库操作和计算结果放入缓存,可以节省很多的执行时间。如图:
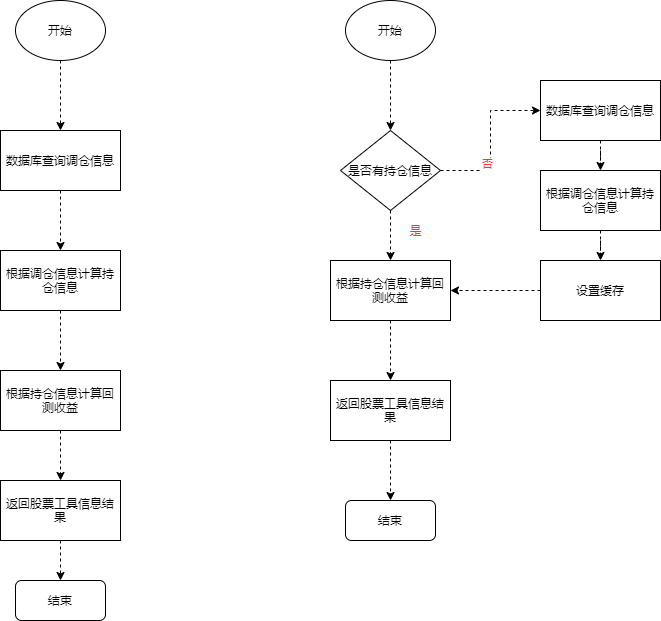
也就是预取思想,就是提前要把查询的数据,提前计算好,放入缓存或者表中的某个字段,用的时候会大幅提高接口性能。跟上面那个例子很像,但是关注点不同。
举个简单的例子:理财产品,会有根据净值计算年化收益率的数据展示需求,利用净值去套用年化收益率计算公式计算的逻辑我们可以采用预处理,这样每一次接口调用直接取对应字段就可以了。
我们都用过数据库连接池,线程池等,这就是池思想的体现,它们解决的问题就是避免重复创建对象或创建连接,可以重复利用,避免不必要的损耗,毕竟创建销毁也会占用时间。
池化思想包含但并不局限于以上两种,总的来说池化思想的本质是预分配与循环使用,明白这个原理后,我们即使是在做一些业务场景的需求时,也可以利用起来。
比如:对象池
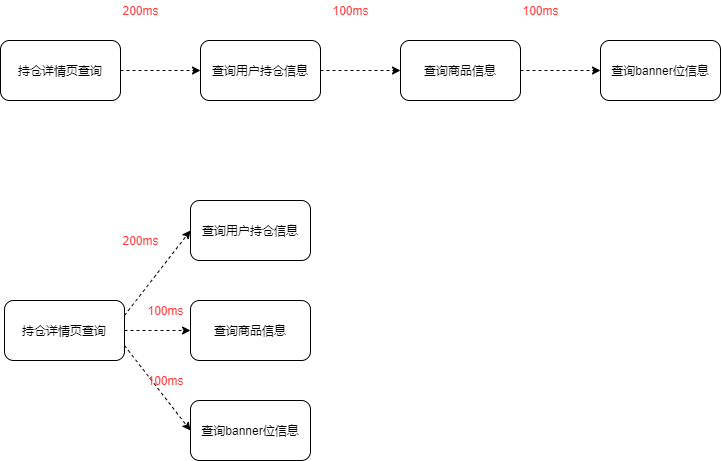
串行就是,当前执行逻辑必须等上一个执行逻辑结束之后才执行,并行就是两个执行逻辑互不干扰,所以并行相对来说就比较节省时间,当然是建立在没有结果参数依赖的前提下。
比如,理财的持仓信息展示接口,我们既需要查询用户的账户信息,也需要查询商品信息和 banner 位信息等等来渲染持仓页,如果是串行,基本上接口耗时就是累加的。如果是并行,接口耗时将大大降低。
如图:
加索引能大大提高数据查询效率,这个在接口设计之出也会考虑到,这里不再多赘述,随着需求的迭代,我们重点整理一下索引不生效的一些场景,希望对小伙伴们有所帮助。
具体不生效场景不再一一举例,后面有时间的话,单独整理一下。
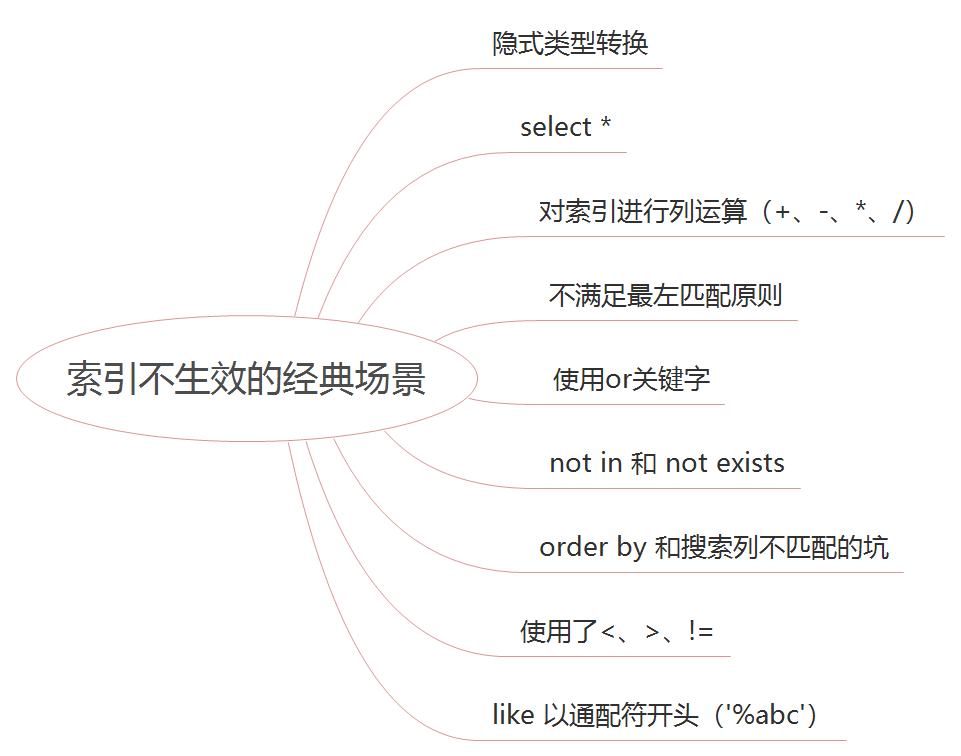
所谓大事务问题,就是运行时间较长的事务,由于事务一致不提交,会导致数据库连接被占用,影响到别的请求访问数据库,影响别的接口性能。
举个例子:
@Transactional(value ="taskTransactionManager", propagation =Propagation.REQUIRED, isolation =Isolation.READ_COMMITTED, rollbackFor ={RuntimeException.class,Exception.class})
publicBasicResultpurchaseRequest(PurchaseRecordrecord){
BasicResult result =newBasicResult();
//插入账户任务
taskMapper.insert(ManagerParamUtil.buildTask(record,TaskEnum.Task_type.pension_account.type(),TaskEnum.Account_bizType.purchase_request.type()));
//插入同步任务
taskMapper.insert(ManagerParamUtil.buildTask(record,TaskEnum.Task_type.pension_sync.type(),TaskEnum.Sync_bizType.purchase.type()));
//插入影像件上传任务
taskMapper.insert(ManagerParamUtil.buildTask(record,TaskEnum.Task_type.pension_sync.type(),TaskEnum.Sync_bizType.cert.type()));
result.setInfo(ResultInfoEnum.SUCCESS);
return result;
}上面这块代码主要是申购申请完成后,执行一系列的后续操作,如果现在新增申购完成后,发送 push 通知用户的需求。很有可能我们会在后面直接追加,如下图所示:事务中嵌套 RPC 调用,即非 DB 操作,这些非 DB 操作如果耗时较大的话,可能会出现大事务问题。大数据引发的问题主要有:死锁、接口超时、主从延迟等。
@Transactional(value ="taskTransactionManager", propagation =Propagation.REQUIRED, isolation =Isolation.READ_COMMITTED, rollbackFor ={RuntimeException.class,Exception.class})
publicBasicResultpurchaseRequest(PurchaseRecordrecord){
BasicResult result =newBasicResult();
...
pushRpc.doPush(record);
result.setInfo(ResultInfoEnum.SUCCESS);
return result;
}所以为避免大事务问题,我们可以通过以下方案规避:
1,RPC 调用不放到事务里面
2,查询操作尽量放到事务之外
3,事务中避免处理太多数据
程序结构问题一般出现在多次需求迭代后,代码叠加形成。会造成一些重复查询、多次创建对象等耗时问题。在多人维护一个项目时比较多见。解决起来也比较简单,我们需要针对接口整体做重构,评估每个代码块的作用和用途,调整执行顺序。
深分页问题比较常见,分页我们一般最先想到的就是 limit ,为什么会慢,我们可以看下这个 SQL:
select*from purchase_record where productCode ='PA9044'andstatus=4orderby orderTime desclimit100000,200limit 100000,200 意味着会扫描 100200 行,然后返回 200 行,丢弃掉前 100000 行。所以执行速度很慢。一般可以采用标签记录法来优化,比如:
select*from purchase_record where productCode ='PA9044'andstatus=4and id >100000limit200这样优化的好处是命中了主键索引,无论多少页,性能都还不错,但是局限性是需要一个连续自增的字段
sql 优化能大幅提高接口的查询性能,由于本文重点讲述接口优化的方案,具体 sql 优化不再一一列举,小伙伴们可以结合索引、分页、等关注点考虑优化方案
锁一般是为了在高并发场景下保护共享资源采用的一种手段,但是如果锁的粒度太粗,会很影响接口性能。
关于锁粒度:就是你要锁的范围有多大,不管是 synchronized 还是 redis 分布式锁,只需要在临界资源处加锁即可,不涉及共享资源的,不必要加锁,就好比你要上卫生间,只需要把卫生间的门锁上就可以,不需要把客厅的门也锁上。
错误的加锁方式:
//非共享资源
privatevoidnotShare(){
}
//共享资源
privatevoidshare(){
}
privateintwrong(){
synchronized(this){
share();
notShare();
}
}正确的加锁方式:
//非共享资源
privatevoidnotShare(){
}
//共享资源
privatevoidshare(){
}
privateintright(){
notShare();
synchronized(this){
share();
}
}科技零售研发中心:商户智能化配置项目
Created by rockyu(余高峰), last modified on Apr 28, 2022
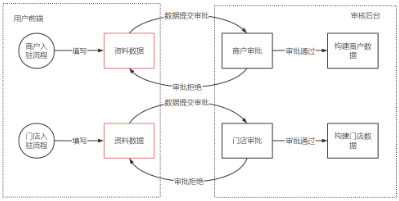
基于以上的这些痛点,我们对商户入驻 和 门店入驻的流程进行了分析,并抽象出了三大核心概念,分别是入驻资料配置化、资料数据统一化 和 入驻流程标准化。后面的细节设计也都是围绕这三个核心概念进行
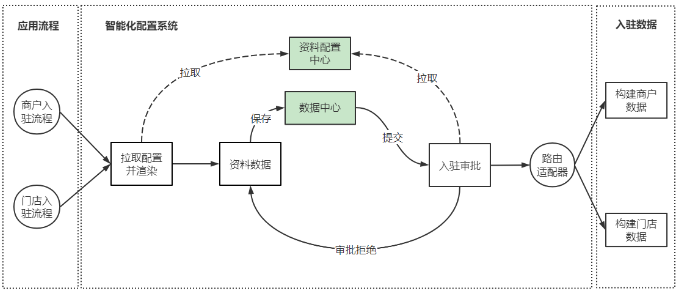
整体设计流程图
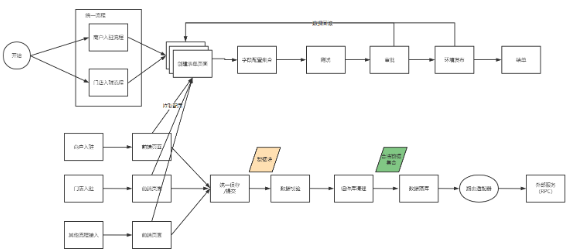
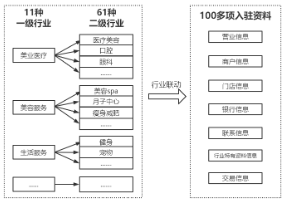
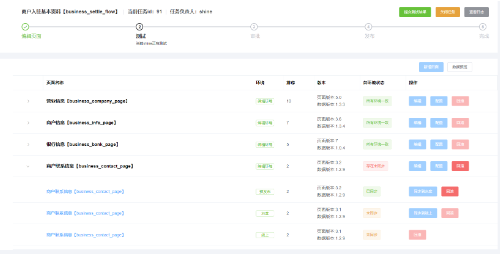
在整个商户入驻和门店入驻的体系中,最核心的就是入驻资料的管控,基于这个问题,我们把商户入驻的资料拆分成了四个模块
如下图所示:
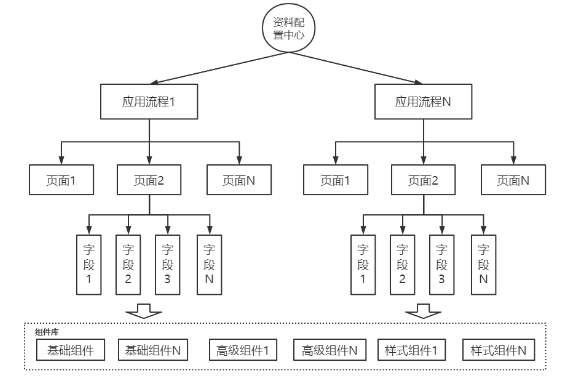
四个模块:
流程:即整个资料的索引ID,用于区分和隔离不同业务之间的资料。
页面:是具体资料的分类,属于流程的子目录,既可以分类展示资料,也可以分模块展示资料
字段:具体的资料配置信息,用于标注资料的数据类型、数据格式、加解密类型等一系列配置信息
组件:定义字段具体的数据格式。组件抽象多个字段的统一数据格式,具有对数据的校验、解析、适配等多种能力。是整个数据中心的处理中心
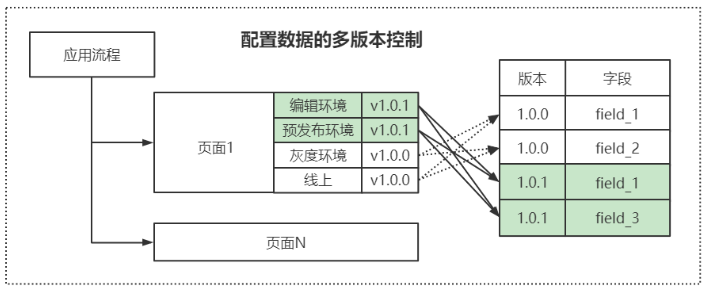
页面分多环境:把页面维度拆分成了两个关键字段,即环境和数据版本
环境:分为编辑环境、预发布、灰度和线上
数据版本:每个环境都有一个数据版本指针,指向字段表中当前环境是引用的哪些字段版本
资料多版本控制
字段版本:每次在编辑环境编辑字段,都是执行的新增操作,并且数据版本加1,编辑之后的页面数据版本指针将指向新的字段应用
高效的数据同步和数据回滚
基于以上的两种结构,我们的数据同步和数据回滚就都只依赖于页面的数据版本索引变更。
同步:就是把各个页面的各个环境的字段版本更新到最新的引用即可
回滚:就是把各个页面的各个环境的字段版本更新到上一次发布的release版本即可
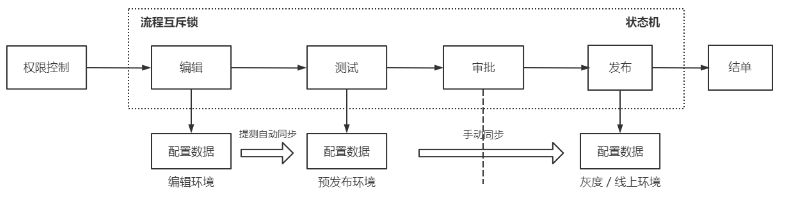
对于资料流程变更的合规性和安全性,我们新增了一个流程对资料的变更进行管控
进一步对入驻资料的分析如下:
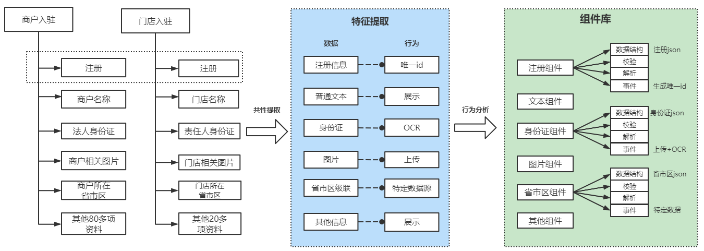
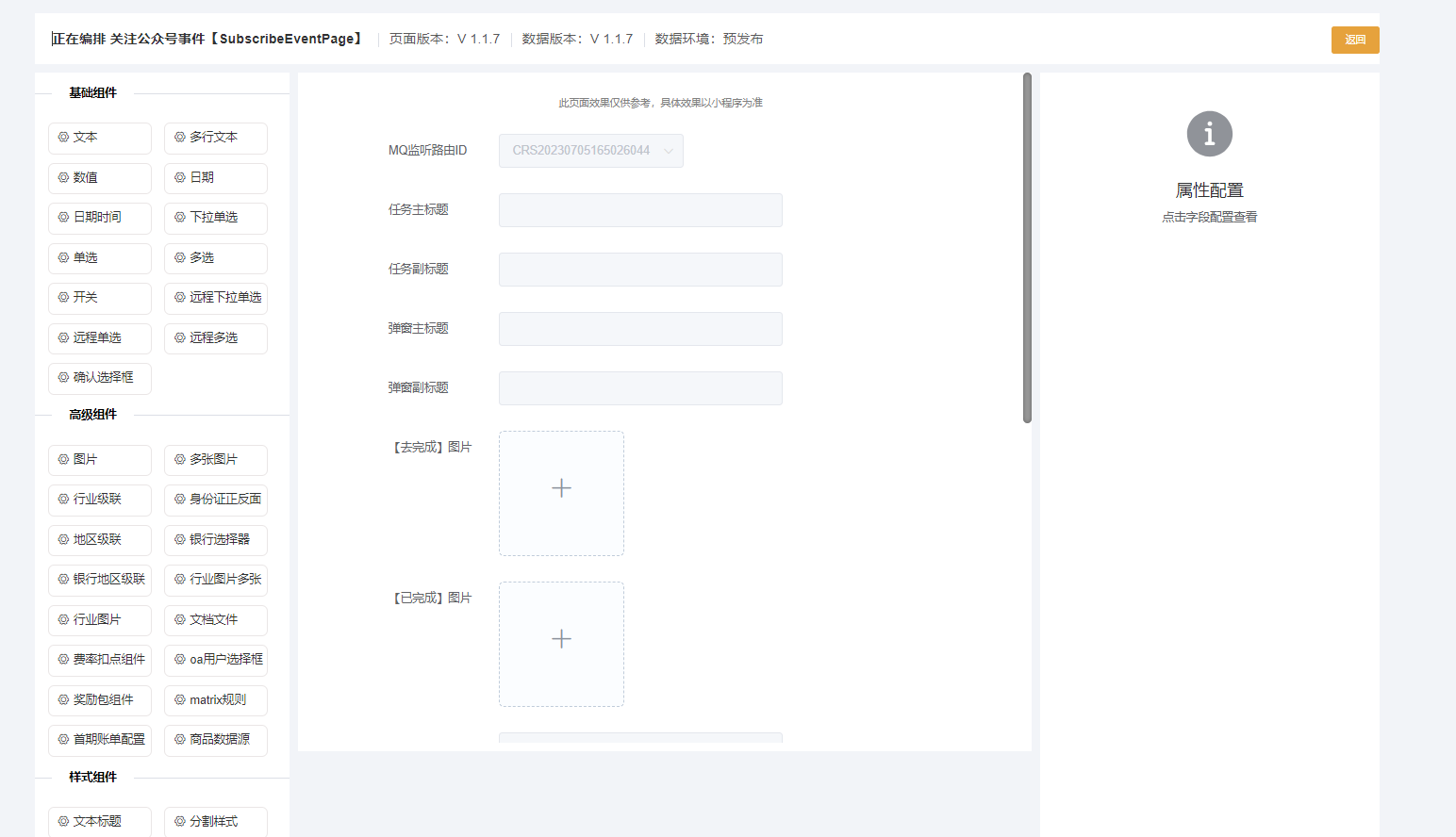
通过资料的共性提取和行为分析,我们从多项资料中,提取出了不同维度的组件类型,分别是高级组件、基础组件和样式组件,而每一种组件都包含了各种的结构。比如身份证组件、图片组件和省市区组件等。
组件库设计:
结构:定义了数据的标准结构。例如普通的String,Integer,还是一个图片的JSON结构或者JSONArray的数据结构
校验:争对前端上传的数据,进行校验,判断当前数据是否满足组件配置的数据结构
解析:对组件数据结果的解析,例如向下传递的时候,需要把一个大的JSON结构平铺之后,向下传递
适配:对于存量历史的数据结构,能够组装适配成 当前组件合法的数据结构
事件:即一个组件的外部事件,比如去调用一个外部接口来获取数据值域或者对数据进行拓展校验等
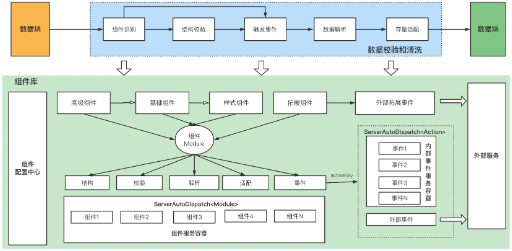
如上图所示,争对前端传入的数据包,需要进行以下的操作步骤:
基于资料的配置化和数据结构的统一化,我们还需要标准化整个数据流程,来统一定义流程。所以抽象了四个标准化接口
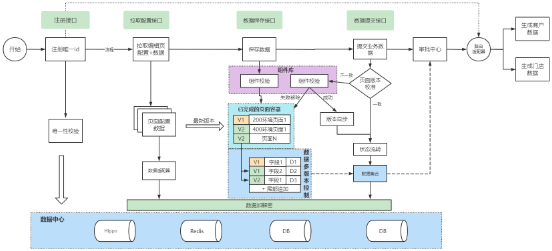
注册接口:用于注册一个唯一的业务ID,所有的业务资料数据都需要挂载在这个业务ID上。
拉取配置接口:拉取配置和数据用于动态渲染,主要是分为两个步骤
拉取配置:拉取资料中心的配置信息,并在前端进行动态渲染
拉取数据:拉取当前业务ID关联的配置信息。并由组件库进行数据适配
保存数据接口:保存页面填写的数据信息到配置系统的库表
1、通过页面和环境拉取配置
2、通过组件校验和清洗数据
3、数据分版本落库
提交数据接口:提交流程所有的页面数据到路由适配器,由路由适配器进行转发
1、页面版本校验,防止在保存和编辑中心存在页面变更的情况
2、页面状态流转
3、提交数据到路由适配器,适配器通过当前流程code执行不同的handler进行入驻
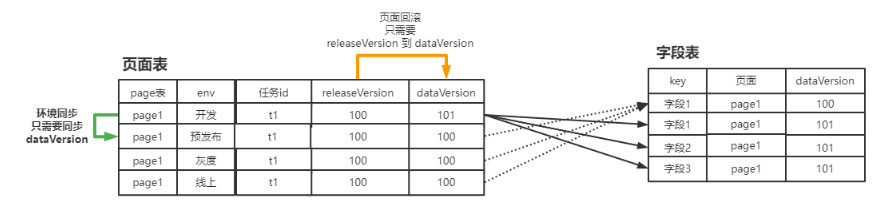
在资料的配置变更过程中,为了提高数据安全和写入效率,引入了数据版本的概念。在页面维度新增了一个dataVersion字段,指向字段表中的dataVersion。
配置编辑:只操作开发环境的页面,并在页面的dataVersion基础上加1,并把新配置的字段追加到字段表尾部。即实现了数据隔离,又提高了写入效率。【dataVersion+1是由版本控制器来协调,保证dataVersion永远都是最新的,防止回滚干扰】
数据同步:只需要把开发环境的dataVerion 同步到 预发布环境即可,无需拷贝字段配置,提高了同步效率
数据回滚:只需要把线上环境的 releasVersion更新到dataVersion,回滚数据指针引用即可。提高了回滚效率,而且支持回滚到历史的任何一个版本
在资料配置的流程管控中,首次采用了afterpay_offline_cola_statemachine状态机引擎。此状态机是基于开源的cola-component-statemachine 4.1.0进行改造的,并且推送到了gitlab上。
代码地址: http://gitlab.fenqile.com/afterpay-offline/afterpay_offline_cola_components/tree/master/afterpay_offline_cola_statemachine
使用wiki: http://wiki.fenqile.com/pages/viewpage.action?pageId=133243839
下图为智能化配置的状态机推演图
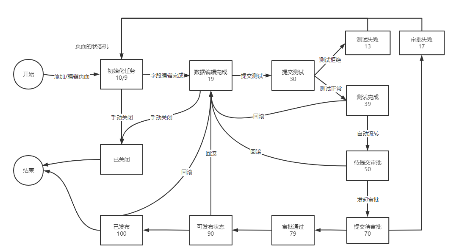
增改资料需求无需开发介入,预计可释放30%以上的人力资源
需求上线时间预计缩短至1天
商户入驻小程序资料变更告别版本兼容,支持动态渲染

rockyu、breakyang
image2022-4-26_13-22-37.png (image/png)
image2022-4-26_13-22-46.png (image/png)
图片2.png (image/png)
image2022-4-26_13-27-43.png (image/png)
image2022-4-26_13-34-27.png (image/png)
image2022-4-26_13-57-55.png (image/png)
image2022-4-26_13-58-23.png (image/png)
image2022-4-26_14-1-18.png (image/png)
图片3.png (image/png)
图片3.png (image/png)
图片4.png (image/png)
图片5.png (image/png)
image2022-4-26_14-25-40.png (image/png)
图片1.png (image/png)
image2022-4-26_15-40-35.png (image/png)
image2022-4-26_15-41-19.png (image/png)
image2022-4-26_15-49-54.png (image/png)
image2022-4-26_15-51-21.png (image/png)
image2022-4-26_16-4-38.png (image/png)
image2022-4-26_16-8-43.png (image/png)
image2022-4-26_16-48-53.png (image/png)
image2022-4-26_16-50-47.png (image/png)
image2022-4-28_18-54-8.png (image/png)
image2022-4-28_18-54-31.png (image/png)
image2022-4-28_18-54-57.png (image/png)
image2022-4-28_19-5-3.png (image/png)
image2022-4-28_19-6-6.png (image/png)
image2022-4-28_19-9-27.png (image/png)
Document generated by Confluence on Dec 20, 2022 17:18
一、新增页面
新增一个页面,用于存放需要配置的各项数据,相当于一个容器
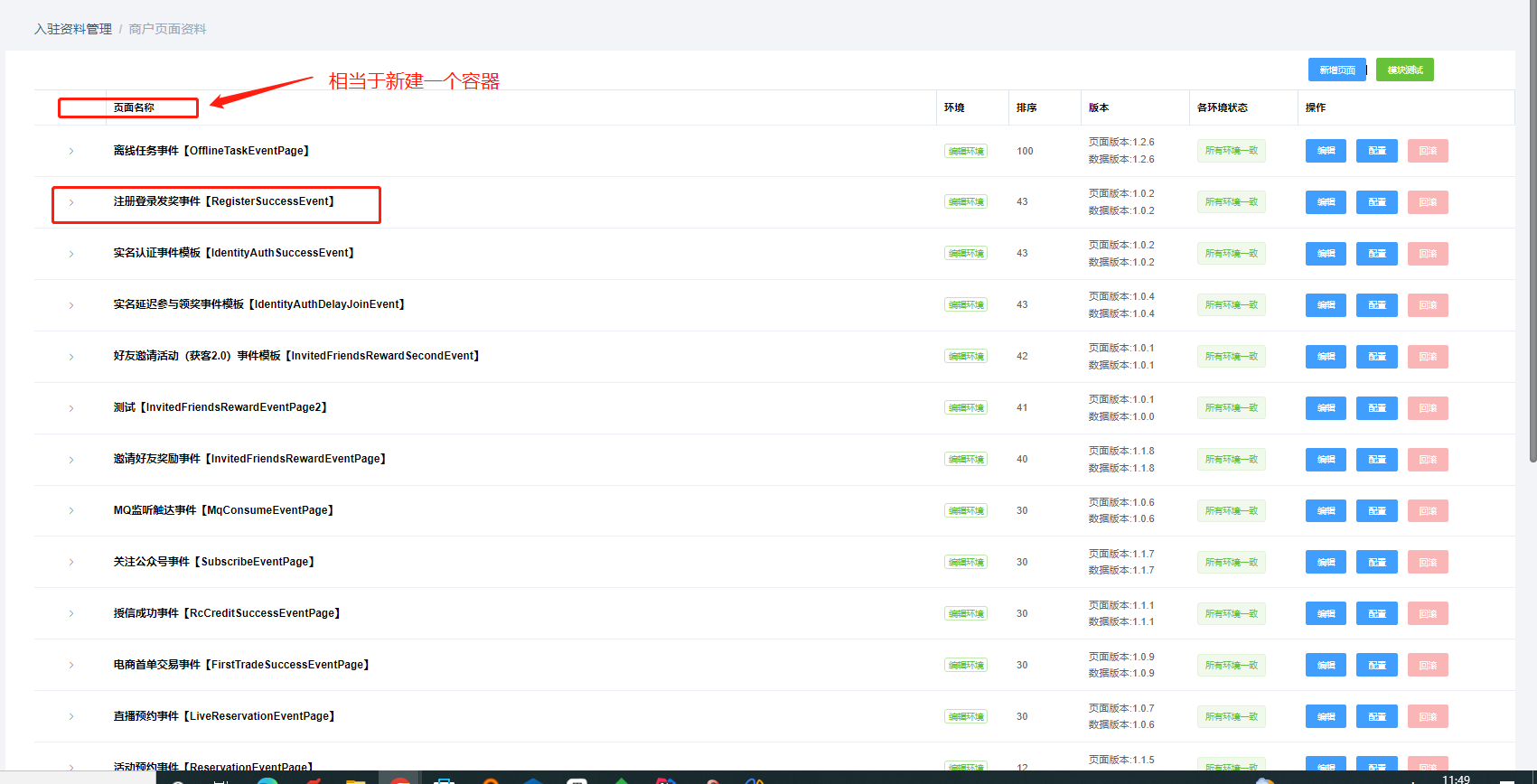
库表设计
CREATE TABLE
t_dynamic_config_page(Fidint(11) NOT NULL AUTO_INCREMENT COMMENT ‘自增id’,Fpage_codevarchar(50) NOT NULL DEFAULT ” COMMENT ‘页面code’,Fflow_codevarchar(50) NOT NULL DEFAULT ” COMMENT ‘流程code’,Fpage_namevarchar(50) NOT NULL DEFAULT ” COMMENT ‘页面名称’,Fpage_describevarchar(255) NOT NULL DEFAULT ” COMMENT ‘页面描述’,Fpage_typevarchar(50) NOT NULL DEFAULT ” COMMENT ‘页面类型’,Fpage_paramsvarchar(1024) NOT NULL DEFAULT ” COMMENT ‘页面的全局参数json格式’,Fsubmit_actionvarchar(1024) NOT NULL DEFAULT ” COMMENT ‘页面的跳转事件’,Fnext_page_codevarchar(50) NOT NULL DEFAULT ” COMMENT ‘成功之后的跳转页’,Fpage_seqint(11) NOT NULL DEFAULT ‘0’ COMMENT ‘页面排序’,Fdata_versionint(11) NOT NULL DEFAULT ‘0’ COMMENT ‘数据版本号’,Fversionint(11) NOT NULL DEFAULT ‘0’ COMMENT ‘乐观锁版本号’,Fenvint(11) NOT NULL DEFAULT ‘100’ COMMENT ‘环境’,Foperatorvarchar(32) NOT NULL DEFAULT ” COMMENT ‘操作人’,Fcreate_timedatetime NOT NULL DEFAULT ‘1970-01-01 00:00:00’ COMMENT ‘创建时间’,Fmodify_timedatetime NOT NULL DEFAULT ‘1970-01-01 00:00:00’ COMMENT ‘修改时间’,Fjg_auto_test_idvarchar(256) NOT NULL DEFAULT ”,Flock_task_idint(11) NOT NULL DEFAULT ‘0’ COMMENT ‘锁页任务id’,Frelease_data_versionint(11) NOT NULL DEFAULT ‘0’ COMMENT ‘f数据发布版本号’,Fshow_field_keyvarchar(255) NOT NULL DEFAULT ” COMMENT ‘在前端展示的字段key’,Frelease_versionint(11) NOT NULL DEFAULT ‘0’ COMMENT ‘页面发布版本号’,
PRIMARY KEY (Fid) USING BTREE,
UNIQUE KEYuniq_Fpage_code(Fpage_code,Fenv) USING BTREE,
KEYidx_Fflow_code(Fflow_code,Fenv) USING BTREE,
KEYidx_Fmodify_time(Fmodify_time) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=326 DEFAULT CHARSET=utf8 COMMENT=’先享后付业务系统|动态配置页面表|20220108′;
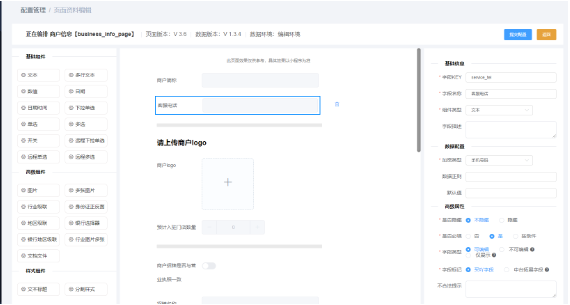
具体设计
在页面上对组件进行拖拽,然后配置每一个字段的属性,最终保存到t_dynamic_config_field (动态字段配置表)
表结构
CREATE TABLE t_dynamic_config_field (Fid int(11) NOT NULL AUTO_INCREMENT COMMENT ‘自增id’,Fpage_code varchar(50) NOT NULL DEFAULT ” COMMENT ‘页面code’,Ffield_key varchar(50) NOT NULL DEFAULT ” COMMENT ‘字段code’,Ffield_name varchar(50) NOT NULL DEFAULT ” COMMENT ‘字段名称’,Ffield_describe varchar(255) NOT NULL DEFAULT ” COMMENT ‘字段描述’,Ffield_module_type varchar(50) NOT NULL DEFAULT ” COMMENT ‘字段组件类型’,Ffield_format varchar(50) NOT NULL DEFAULT ” COMMENT ‘字段格式 邮箱,手机号等’,Ffield_value_type varchar(50) NOT NULL DEFAULT ” COMMENT ‘字段值类型’,Ffield_value_regex varchar(255) NOT NULL DEFAULT ” COMMENT ‘字段值正则校验’,Ffield_default_value varchar(255) NOT NULL DEFAULT ” COMMENT ‘字段默认值’,Ffield_required int(11) NOT NULL DEFAULT ‘0’ COMMENT ‘字段是否必填 0表示不必填 1表示必填 2表示按照规则必填’,Ffield_required_rule varchar(1024) NOT NULL DEFAULT ” COMMENT ‘字段是否必填的规则,当Ffield_required=2的时候生效’,Ffield_hide int(11) NOT NULL DEFAULT ‘0’ COMMENT ‘字段是否隐藏 0表示不隐藏 1表示隐藏’,Ffield_show_rule varchar(1024) NOT NULL DEFAULT ” COMMENT ‘字段展示规则 Ffield_hide=1生效’,Ffield_hint_msg varchar(255) NOT NULL DEFAULT ” COMMENT ‘字段不合法提示文案’,Ffield_function varchar(255) NOT NULL DEFAULT ” COMMENT ‘自定义规则函数(保留字段)’,Ffield_event varchar(255) NOT NULL DEFAULT ” COMMENT ‘方法事件(保留字段)’,Fdata_version int(11) NOT NULL DEFAULT ‘0’ COMMENT ‘数据版本号’,Fversion int(11) NOT NULL DEFAULT ‘0’ COMMENT ‘版本号’,Foperator varchar(32) NOT NULL DEFAULT ” COMMENT ‘操作人’,Fcreate_time datetime NOT NULL DEFAULT ‘1970-01-01 00:00:00’ COMMENT ‘创建时间’,Fmodify_time datetime NOT NULL DEFAULT ‘1970-01-01 00:00:00’ COMMENT ‘修改时间’,Ffield_seq int(11) NOT NULL DEFAULT ‘0’ COMMENT ‘字段排序’,Fjg_auto_test_id varchar(256) NOT NULL DEFAULT ”,Ffield_value_range varchar(1024) NOT NULL DEFAULT ” COMMENT ‘字段的值域范围’,Ffield_flag int(11) NOT NULL DEFAULT ‘0’ COMMENT ‘字段标记 0表示买吖字段 1表示中台扩展字段’,Ffield_type int(11) NOT NULL DEFAULT ‘0’ COMMENT ‘字段类型 0表示可编辑 1表示只读 2表示只展示’,Ffield_disable int(11) NOT NULL DEFAULT ‘0’ COMMENT ‘字段是是否禁用 0表示不禁用 1表示禁用 2表示按照规则禁止’,Ffield_disable_rule varchar(1024) NOT NULL DEFAULT ” COMMENT ‘字段是否禁用的规则,当Ffield_disable=2的时候生效’,
PRIMARY KEY (Fid) USING BTREE,
UNIQUE KEY uniq_Fpage_code_Ffield_key (Fpage_code,Fdata_version,Ffield_key),
KEY idx_Fmodify_time (Fmodify_time) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=12839 DEFAULT CHARSET=utf8 COMMENT=’先享后付业务系统|动态配置元素字段表|20220108′;
{
“status”: 200
,”message”: “”
,”total”: 8
,”rows”: {
“item”: [{
“id”: “10001”
}]
}
}
(58条消息) Field injection is not recommended(Spring团队不推荐使用Field注入)_编程火箭车的博客-CSDN博客
(58条消息) 表达式引擎Aviator基本介绍及使用以及基于Aviator的规则引擎(附代码详细介绍)_com.googlecode.aviator_弹弹霹雳的博客-CSDN博客
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}