Spring团队不推荐使用Field注入
(58条消息) Field injection is not recommended(Spring团队不推荐使用Field注入)_编程火箭车的博客-CSDN博客
(58条消息) Field injection is not recommended(Spring团队不推荐使用Field注入)_编程火箭车的博客-CSDN博客
今天在进行开发的时候,发现Controller 里面 的方法参数 可以用 @ModelAttribute 修饰
之前用过 @RequestBody、@RequetParam、@PathVariable 注解修饰 参数 ,@ModelAttribute 还是头一次见到,特此补充
@ModelAttribute的用法大概有两种:
两种标记的方法产生效果也各不相同
注:用@ModelAttribute 修饰的方法会先于请求的方法执行!!!
@Controller
@RequestMapping(value=”model”)
public class ModelAttributeTest {
@ModelAttribute
public void init()
{
System.out.println(“最先执行的方法”);
}
@ModelAttribute
public void init02()
{
System.out.println(“最先执行的方法02”);
}
@RequestMapping(value=”modelTest.do”)
public String modelTest()
{
System.out.println(“然后执行的方法”);
return “modelTest”;
}
@ModelAttribute
public void init03()
{
System.out.println(“最先执行的方法03”);
}
}
部署后运行,点击页面测试按钮,查看控制台输出,这个时候你会发现,后台控制器并没有直接进入modelTest.do的路径,而是先执行了被@ModelAttribute标记的init方法。应该这么理解,当同一个controller中有任意一个方法被@ModelAttribute注解标记,页面请求只要进入这个控制器,不管请求那个方法,均会先执行被@ModelAttribute标记的方法,所以我们可以用@ModelAttribute注解的方法做一些初始化操作。当同一个controller中有多个方法被@ModelAttribute注解标记,所有被@ModelAttribute标记的方法均会被执行,按先后顺序执行,然后再进入请求的方法。

点击测试页面,会发现当两个注解同时注解到一个方法上时,方法的返回值会变成model模型的返回值,key是标记的名
@Controller
@RequestMapping(value=”model”)
public class ModelAttributeTest {
@RequestMapping(value=”modelTest.do”)
public String modelTest(@ModelAttribute(“pojo”) PojoTest pojo)
{
try {
pojo.setUserName(new String(pojo.getUserName().getBytes(“iso-8859-1″),”utf-8”));
pojo.setSex(new String(pojo.getSex().getBytes(“iso-8859-1″),”utf-8”));
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(pojo);
return “modelTest”;
}
}
点击页面测试,页面文本框会显示URL地址传递过来的参数,因为SpringMVC会自动匹匹配页面传递过来的参数的name属性和后台控制器中的方法中的参数名,如果参数名相同,会自动匹配,如果控制器中方法是封装的bean,会自动匹配bean中的属性,其实这种取值方式不需要用@ModelAttribute注解,只要满足匹配要求,也能拿得到值
作用:
i) 该注解用于读取Request请求的body部分数据,使用系统默认配置的HttpMessageConverter进行解析,然后把相应的数据绑定到要返回的对象上;
ii) 再把HttpMessageConverter返回的对象数据绑定到 controller中方法的参数上。
使用时机:
A) GET、POST方式提时, 根据request header Content-Type的值来判断:
B) PUT方式提交时, 根据request header Content-Type的值来判断:
说明:request的body部分的数据编码格式由header部分的Content-Type指定;
今天在公司学习项目代码的时候看到了
private static final long serialVersionUID = 1L;
特此记录
1、首先谈谈为什么要序列化对象
– 把对象转换为字节序列的过程称为对象的序列化。
– 把字节序列恢复为对象的过程称为对象的反序列化。
对象的序列化主要有两种用途:
1) 把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中;
2) 在网络上传送对象的字节序列。
在很多应用中,需要对某些对象进行序列化,让它们离开内存空间,入住物理硬盘,以便长期保存。比如最常见的是Web服务器中的Session对象,当有 10万用户并发访问,就有可能出现10万个Session对象,内存可能吃不消,于是Web容器就会把一些seesion先序列化到硬盘中,等要用了,再把保存在硬盘中的对象还原到内存中。
当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象
2、为什么要使用SerialversionUID呢
简单看一下 Serializable接口的说明
If a serializable class does not explicitly declare a serialVersionUID,
then the serialization runtime will calculate a default
serialVersionUID value for that class based on various aspects of the class,
as described in the Java(TM) Object Serialization Specification.
如果用户没有自己声明一个serialVersionUID,接口会默认生成一个serialVersionUID
However, it is stronglyrecommended that all serializable classes explicitly declareserialVersionUID values, since the default serialVersionUID computation is highly sensitive to class details that may vary depending on compiler implementations, and can thus result in unexpectedInvalidClassExceptions during deserialization.
但是强烈建议用户自定义一个serialVersionUID,因为默认的serialVersinUID对于class的细节非常敏感,反序列化时可能会导致InvalidClassException这个异常。
其实也可以这样理解,相当于快递的打包和拆包,里面的东西要保持一致,不能人为的去改变他,不然就交易不成功。 序列化与反序列化也是一样,而版本号的存在就是要是里面内容要是不一致,不然就报错。像一个防伪码一样。
之前接触过加密算法,粗略了解到对称算法,非对称算法,不可逆算法等等
正好本次项目中用到了 MD5加密,特此详解MD5加密算法
MD5是一个安全的散列算法,输入两个不同的明文不会得到相同的输出值,根据输出值,不能得到原始的明文,即其过程不可逆;所以要解密MD5没有现成的算法,只能用穷举法,把可能出现的明文,用MD5算法散列之后,把得到的散列值和原始的数据形成一个一对一的映射表,通过比在表中比破解密码的MD5算法散列值,通过匹配从映射表中找出破解密码所对应的原始明文
对信息系统或者网站系统来说,MD5算法主要用在用户注册口令的加密,对于普通强度的口令加密,可以通过以下三种方式进行破解:
(1)在线查询密码。一些在线的MD5值查询网站提供MD5密码值的查询,输入MD5密码值后,如果在数据库中存在,那么可以很快获取其密码值。
(2)使用MD5破解工具。网络上有许多针对MD5破解的专用软件,通过设置字典来进行破解。
(3)通过社会工程学来获取或者重新设置用户的口令。
因此简单的MD5加密是没有办法达到绝对的安全的,因为普通的MD5加密有多种暴力破解方式,因此如果想要保证信息系统或者网站的安全,需要对MD5进行改造,增强其安全性,本文就是在MD5加密算法的基础上进行改进!
MD5以512位分组来处理输入的信息,且每一分组又被划分为16个32位子分组,经过了一系列的处理后,算法的输出由四个32位分组组成,将这四个32位分组级联后将生成一个128位散列值。
在MD5算法中,首先需要对信息进行填充,使其字节长度对512求余数的结果等于448。因此,信息的字节长度(Bits Length)将被扩展至N*512+448,即N*64+56个字节(Bytes),N为一个正整数。填充的方法如下,在信息的后面填充一个1和无数个0,直到满足上面的条件时才停止用0对信息的填充。然后再在这个结果后面附加一个以64位二进制表示的填充前的信息长度。经过这两步的处理,现在的信息字节长度=N*512+448+64=(N+1)*512,即长度恰好是512的整数倍数。这样做的原因是为满足后面处理中对信息长度的要求。MD5中有四个32位被称作链接变量(Chaining Variable)的整数参数,他们分别为:A=0x01234567,B=0x89abcdef,C=0xfedcba98,D=0x76543210。当设置好这四个链接变量后,就开始进入算法的四轮循环运算,循环的次数是信息中512位信息分组的数目。
将上面四个链接变量复制到另外四个变量中:A到a,B到b,C到c,D到d。主循环有四轮(MD4只有三轮),每轮循环都很相似。第一轮进行16次操作。每次操作对a、b、c和d中的其中三个作一次非线性函数运算,然后将所得结果加上第四个变量(文本中的一个子分组和一个常数)。
再将所得结果向右环移一个不定的数,并加上a、b、c或d中之一。最后用该结果取代a、b、c或d中之一。以一下是每次操作中用到的四个非线性函数(每轮一个)。

其中,?是异或,∧是与,∨是或,是反符号。
如果X、Y和Z的对应位是独立和均匀的,那么结果的每一位也应是独立和均匀的。F是一个逐位运算的函数。即,如果X,那么Y,否则Z。函数H是逐位奇偶操作符。所有这些完成之后,将A,B,C,D分别加上a,b,c,d。然后用下一分组数据继续运行算法,最后的输出是A,B,C和D的级联。最后得到的A,B,C,D就是输出结果,A是低位,D为高位,DCBA组成128位输出结果。
从安全的角度讲,MD5的输出为128位,若采用纯强力攻击寻找一个消息具有给定Hash值的计算困难性为2128,用每秒可试验1000000000个消息的计算机需时1.07×1022年。若采用生日攻击法,寻找有相同Hash值的两个消息需要试验264个消息,用每秒可试验1000000000个消息的计算机需时585年。
MD5加密算法由于其具有较好的安全性,加之商业也可以免费使用该算法,因此该加密算法被广泛使用,md5算法主要运用在数字签名、文件完整性验证以及口令加密等方面。
在目前的信息系统中,对md5加密方法的利用主要通过在脚本页面中引用包含md5加密函数代码的文件,以asp脚本为例,在需要调用的页面中加入,md5.asp为md5加密函数代码文件,然后直接调用函数MD5(sMessage)即可,md5加密后的值有16位和32位之分,如果在md5加密函数中使用的是MD5 = LCase(WordToHex(a) &WordToHex(b) & WordToHex(c) & WordToHex(d)),则表示是32位,如果使用的是MD5=LCase(WordToHex(b) & WordToHex(c)),则表示是16位。例如对明文为“123456”的值进行加密,其md5值有两个,如下所示:
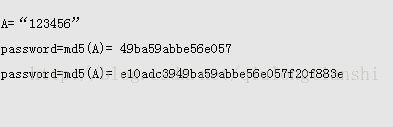
A=123456password=md5(A)= 49ba59abbe56e057 password=md5(A)=10adc3949ba59abbe56e057f20f883e如果将加密的md5值直接保存在数据库,当网站存在注入或者其它漏洞时,入侵者极有可能获取用户的密码值,通过md5在如果将加密的md5值直接保存在数据库,当网站存在注入或者其它漏洞时,入侵者极有可能获取用户的密码值,通过md5在线查询或者暴力破解可以得到密码。
本文提到的方法是在使用md5加密算法对明文(口令)加密的基础上,对密文进行了改变,在密文中截取一段数据并丢弃,然后使用随机函数填充被丢弃的数据,且整个过程不改变md5加密后的位数。其加密过程用算法描述如下:
(1)对明文password进行md5加密,获得密文md5(password)。
(2)使用截取函数截取加密后的密文,从第beginnumber位置开始截取number位数值,得到密码A,其中A=left(md5(password),beginnumber-1)。
(3)使用截取函数截取加密后的明文的number位数后的值B,其中 B=right(md5(password),md5-digit -(beginnumber+number-1))。
(4)使用随机函数gen_key(number)填充被截取的number的值。
(5)变换后的密码值为encrypt_password =A&get_key(number)&B
变量说明:

解密过程跟加密过程有些类似,先对输入的明文进行加密,接着从beginnumber处截取前半部分得到A′,后半部分得到B′,然后从数据库中读出密码中的A和B部分,最后如果A=A′并且B=B′,则认为用户输入的密码跟数据库中的密码是匹配的。
当然,这只是改进 MD5 算法的一种方法,实际可行的思路有很多
有人也曾经提出对md5加密算法中的函数或者变量进行修改,从而加强在使用原md5算法的安全,但是这种方法修改了md5原函数或者变量后,无法验证修改后md5算法在强度上是否跟原算法一致。本文提出的方法是在原有md5加密的基础上,通过对密文截取一定位数的字符串,并使用随机数进行填充,最后得到的密文虽然是经过md5加密,但是其值已经大不一样,因此通过md5常规破解方法是永远也不能破解其原始密码值,从而保证了数据的安全。虽然目前有很多攻击方法,诸如SQL注入、跨站攻击等,可以较容易的获取数据库中的值,通过本方法进行加密,在网站或者系统代码泄露前,其数据是相对安全的,因此具有一定参考加值。
</span> <span class="fr"> <span class="fl" th:if="${session.user == null}">你好,请<a href="/login.html" style="color:#ff4e00;">登录</a> <a href="/register" style="color:#ff4e00;">免费注册</a> </span> <span class="fl" th:if="${session.user != null}"><a href="/user/userInfo" >欢迎回来,<span th:text="${session.user.userName}"></span></a> | <a href="/orders/list">我的订单</a> </span> <span class="fl" th:if="${session.user != null} and ${session.user.role != 0}">| <a href="/admin/adminIndex">后台管理 </a></span> <span class="fl" th:if="${session.user != null}">| <a href="/admin/adminIndex">秒杀商品 </a></span> <span class="fl" th:if="${session.user != null}">| <a href="/user/logout">注销</a></span> </span> 注意:多条件下使用 th:if 格式为 <span class="fl" th:if="${session.user != null} and ${session.user.role != 0}">| <a href="/admin/adminIndex">后台管理 </a></span>
前面的学习中,我们完成了防止超卖商品和抢购接口的限流,已经能够防止大流量把我们的服务器直接搞炸,这篇文章中,我们要开始关心一些细节问题,我们现在设计的系统中还有一些问题
1.我们应该在一定时间内执行秒杀处理,不能在任意时间都接收秒杀请求,如何加入时间验证?
2.对于现有的接口,暴露了我们的接口地址,然后通过脚本抢购怎么办?
3.秒杀开始之后如何限制单个用户的请求频率,即单位时间内的访问次数?
此节内容解决:
限时抢购的实现
使用Redis来记录秒杀商品的时间,对秒杀过期的请求进行拒绝处理


秒杀请求被拦截:

数据库无改变,即未卖出

Redis 抢购时间可以自己设置,通过传参
通过乐观锁防止超卖+令牌桶限流
//开发一个秒杀方法 乐观锁防止超卖,令牌桶限流
@GetMapping("/killtoken")
public String killtoken(Integer id){
LOGGER.info("秒杀商品的 ID = " + id);
//加入令牌桶的限流措施
//注意:限流之后商品不能百分百的卖掉,有些请求被抛弃,保留一小部分的商品
if(!rateLimiter.tryAcquire(2,TimeUnit.SECONDS)){
return "抢购失败,当前秒杀活动过于火爆,请重试!";
}
try {//根据秒杀商品的 ID 调用秒杀业务
int orderId = orderService.kill(id);
return "秒杀成功!订单ID为:" + orderId;
}catch (Exception e){
e.printStackTrace();
return e.getMessage();
}
}
会出现商品剩余的情况,因为在接口限流时有一部分请求被抛弃
 查看数据库卖出的商品数量:
查看数据库卖出的商品数量:
 如果想多卖一点怎么办呢?
1.并发请求加多(Jmeter测试)
2.尝试获取令牌桶的时间+1s
3.增加令牌桶初始大小
如果想多卖一点怎么办呢?
1.并发请求加多(Jmeter测试)
2.尝试获取令牌桶的时间+1s
3.增加令牌桶初始大小



引入依赖 guava
<!-- Google接口限流 guava RateLimter 令牌桶实现--> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>30.1.1-jre</version> </dependency> 既然是接口限流,那么一般将限流放在控制器Controller
@GetMapping("/sale")
public String sale(Integer id){
//1.没有获取到 token 请求 直到获取到 token 令牌
LOGGER.info("等待的时间:" + rateLimiter.acquire());//试图拿到令牌
//2.设置一个等待的时间,如果在等待的时间内获取到了 token 令牌,则处理业务,如果在等待时间内没有获取到相应的 token 则抛弃请求
if(!rateLimiter.tryAcquire(5, TimeUnit.SECONDS)){
System.out.println("当前请求被限流,直接抛弃,无法调用后续秒杀逻辑......");
return "抢购失败!";
}
System.out.println("处理业务..................");
return "测试令牌桶";
}
令牌桶原理:先获取令牌,再执行业务逻辑

使用同步代码块,效率低下,因此改为乐观锁
StockMapper
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.southwind.mmall002.mapper.StockMapper">
<!--根据商品 ID 扣除库存-->
<update id="updateSale" parameterType="com.southwind.mmall002.entity.kill.Stock">
update stock
set
saled=saled + 1,
version = version + 1
where
id = #{id}
and
version = #{version}
</update>
</mapper>
Service层代码
public Integer kill(Integer id, HttpSession session) {
//根据 商品 ID 校验库
Stock stock = checkStock(id);
LOGGER.info("商品的名称为:" + stock.getName());
LOGGER.info("商品的已售为:" + stock.getSaled());
LOGGER.info("商品的库存为:" + stock.getCount());
//更新库存
updateSale(stock);
//创建订单
return createOrder(stock,session);
}
//校验库存
private Stock checkStock(Integer id){
Stock stock = stockMapper.selectById(id);
if(stock.getSaled().equals(stock.getCount())){
throw new RuntimeException("库存不足!!!");
}
return stock;
}
//扣除库存
private void updateSale(Stock stock){
LOGGER.info("准备更新库存...");
//在 SQL 层面完成销量的+1 和 版本号的+1 并且根据商品 ID 和版本号同时查询更新的商品
stock.setSaled(stock.getSaled() + 1);
int updateRows = stockMapper.updateSale(stock);//返回更新的条数
if(updateRows == 0 ){
throw new RuntimeException("抢购失败,请重试!!!");
}
}
//创建订单
private Integer createOrder(Stock stock,HttpSession session){
User user= (User) session.getAttribute("user");
Orders orders = new Orders();
orders.setUserId(user.getId());
orders.setLoginName(user.getLoginName());
orders.setSerialnumber(stock.getName());
orderMapper.insert(orders);
return orders.getId();
}
}
结果:实现了线程同步