在学习计算机网络协议的时候,出现过HTTP无状态的介绍,但当时只是简单的理解为服务器与客户端的第二次会话无法辨别。
即,第一次会话,C — S;第二次会话,S无法分别C还是不是第一次的那个C
但我个人感觉这样的理解可能会有偏差,因此查阅资料,进行整理
且看案例:
另外一个维度的分析:
https://www.zhihu.com/question/23202402/answer/527748675
摘要:
作者:灵剑
链接:https://www.zhihu.com/question/23202402/answer/527748675
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
HTTP所谓的“无状态协议”,其实跟Cookies、Session这些都没有什么大的联系,它描述的主要是通信协议层面的问题。
常见的许多七层协议实际上是有状态的,例如SMTP协议,它的第一条消息必须是HELO,用来握手,在HELO发送之前其他任何命令都是不能发送的;接下来一般要进行AUTH阶段,用来验证用户名和密码;接下来可以发送邮件数据;最后,通过QUIT命令退出。可以看到,在整个传输层上,通信的双方是必须要时刻记住当前连接的状态的,因为不同的状态下能接受的命令是不同的;另外,之前的命令传输的某些数据也必须要记住,可能会对后面的命令产生影响。这种就叫做有状态的协议。(1.连接的状态要记住 2.之前发送的命令要记住)
相反,为什么说HTTP是无状态的协议呢?因为它的每个请求都是完全独立的,每个请求包含了处理这个请求所需的完整的数据,发送请求不涉及到状态变更。(对应上述的有状态的协议,即首先连接不分阶段,连接上了就连上了,其次就是不需要记住之前的命令,因为每个请求包含了所有的信息)即使在HTTP/1.1上,同一个连接允许传输多个HTTP请求的情况下,如果第一个请求出错了,后面的请求一般也能够继续处理(当然,如果导致协议解析失败、消息分片错误之类的自然是要除外的)可以看出,这种协议的结构是要比有状态的协议更简单的,一般来说实现起来也更简单,不需要使用状态机,一个循环就行了——不过,HTTP本身很复杂,这是另一个故事了,这里暂时不提。
无状态的协议有一些优点,也有一些缺点。
和许多人想象的不同,会话(Session)支持其实并不是一个缺点,反而是无状态协议的优点,因为对于有状态协议来说,如果将会话状态与连接绑定在一起,那么如果连接意外断开,整个会话就会丢失,重新连接之后一般需要从头开始(当然这也可以通过吸收无状态协议的某些特点进行改进);而HTTP这样的无状态协议,使用元数据(如Cookies头)来维护会话,使得会话与连接本身独立起来,这样即使连接断开了,会话状态也不会受到严重伤害,保持会话也不需要保持连接本身。另外,无状态的优点还在于对中间件友好,中间件无需完全理解通信双方的交互过程,只需要能正确分片消息即可,而且中间件可以很方便地将消息在不同的连接上传输而不影响正确性,这就方便了负载均衡等组件的设计。
无状态协议的主要缺点在于,单个请求需要的所有信息都必须要包含在请求中一次发送到服务端,这导致单个消息的结构需要比较复杂,必须能够支持大量元数据,因此HTTP消息的解析要比其他许多协议都要复杂得多。同时,这也导致了相同的数据在多个请求上往往需要反复传输,例如同一个连接上的每个请求都需要传输Host、Authentication、Cookies、Server等往往是完全重复的元数据,一定程度上降低了协议的效率。(缺点是请求更复杂,占用的空间更多,效率更低)
协议的状态是指下一次传输数据的时候能考虑到这次传输信息的状态。也有是说有状态协议以前的请求导致协议所处的状态会影响后续的状态,协议会根据上一个状态创建上下文。
http协议里就是无状态协议不用考虑上下文;每个请求都是与服务器的独立连接,即下一次请求到来的时候协议不用维护这次请求中客户机-服务器间交互的信息。
今天学习的时候看到了Redis的pipeline,因为对这方面不甚了解,所以特地找了相关资料,并进行个人总结
什么是Pipeline?
可以将其解释为管道,流水线。如果站在软件架构的角度来说,Pipeline是一种通信架构。
为什么要有Pipeline?
这里以Redis的Pipeline来说明。
(一)简介
Redis 使用的是客户端-服务器(CS)模型和请求/响应协议的 TCP 服务器。这意味着通常情况下一个请求会遵循以下步骤:
- 客户端向服务端发送一个查询请求,并监听 Socket 返回,通常是以阻塞模式,等待服务端响应。
- 服务端处理命令,并将结果返回给客户端。
Redis 客户端与 Redis 服务器之间使用 TCP 协议进行连接,一个客户端可以通过一个 socket 连接发起多个请求命令。每个请求命令发出后 client 通常会阻塞并等待 redis 服务器处理,redis 处理完请求命令后会将结果通过响应报文返回给 client,因此当执行多条命令的时候都需要等待上一条命令执行完毕才能执行。比如:
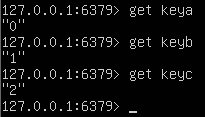
其执行过程如下图所示: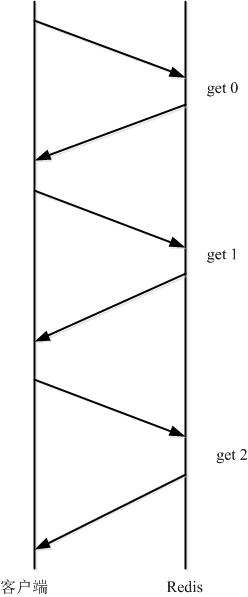
由于通信会有网络延迟,假如 client 和 server 之间的包传输时间需要0.125秒。那么上面的三个命令6个报文至少需要0.75秒才能完成。这样即使 redis 每秒能处理100个命令,而我们的 client 也只能一秒钟发出四个命令。这显然没有充分利用 redis 的处理能力。
而管道(pipeline)可以一次性发送多条命令并在执行完后一次性将结果返回,pipeline 通过减少客户端与 redis 的通信次数来实现降低往返延时时间,而且 Pipeline 实现的原理是队列,而队列的原理是时先进先出,这样就保证数据的顺序性。 Pipeline 的默认的同步的个数为53个,也就是说 arges 中累加到53条数据时会把数据提交。其过程如下图所示:client 可以将三个命令放到一个 tcp 报文一起发送,server 则可以将三条命令的处理结果放到一个 tcp 报文返回。
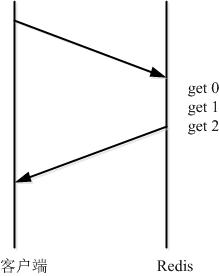
需要注意到是用 pipeline 方式打包命令发送,redis 必须在处理完所有命令前先缓存起所有命令的处理结果。打包的命令越多,缓存消耗内存也越多。所以并不是打包的命令越多越好。具体多少合适需要根据具体情况测试。
(二)比较普通模式与 PipeLine 模式
测试代码可参考原文链接:
https://blog.csdn.net/u011489043/article/details/78769428
(三)适用场景(可靠性,实时性)
有些系统可能对可靠性要求很高,每次操作都需要立马知道这次操作是否成功,是否数据已经写进 redis 了,那这种场景就不适合。
还有的系统,可能是批量的将数据写入 redis,允许一定比例的写入失败,那么这种场景就可以使用了,比如10000条一下进入 redis,可能失败了2条无所谓,后期有补偿机制就行了,比如短信群发这种场景,如果一下群发10000条,按照第一种模式去实现,那这个请求过来,要很久才能给客户端响应,这个延迟就太长了,如果客户端请求设置了超时时间5秒,那肯定就抛出异常了,而且本身群发短信要求实时性也没那么高,这时候用 pipeline 最好了。
(四)管道(Pipelining) VS 脚本(Scripting)
管道和事务是不同的,pipeline只是表达“交互”中操作的传递的方向性,pipeline也可以在事务中运行,也可以不在。无论如何,pipeline中发送的每个command都会被server立即执行,如果执行失败,将会在此后的相应中得到信息;也就是pipeline并不是表达“所有command都一起成功”的语义,管道中前面命令失败,后面命令不会有影响,继续执行。简单来说就是管道中的命令是没有关系的,它们只是像管道一样流水发给server,而不是串行执行,仅此而已;但是如果pipeline的操作被封装在事务中,那么将有事务来确保操作的成功与失败。
使用管道可能在效率上比使用script要好,但是有的情况下只能使用script。因为在执行后面的命令时,无法得到前面命令的结果,就像事务一样,所以如果需要在后面命令中使用前面命令的value等结果,则只能使用script或者事务+watch。
参考链接:
1.https://blog.csdn.net/w1lgy/article/details/84455579?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.no_search_link
2.https://blog.csdn.net/fangjian1204/article/details/50585080
3.https://blog.csdn.net/u011489043/article/details/78769428